Automatic XPath Construction
Any element on a web page may be found by its XPath. Moreover, it is possible to locate the same element using a number of different XPath statements. For example:
//a[5]
/html/body/ul/li[5]/a
//a[@id='lnk5']
All three may point to the same element.
By default Rapise will construct an XPath statement meeting the following requirements:
- Universal: should work on different browsers equally.
- Short: whenever possible try to locate an element by its unique attributes. I.e. use:
//a[@id='lnk5']
instead of the full path
/html/body/ul/li[5]/a
See Elastic XPATH Expressions article for more details.
XPath limitations
- XPath is able to search for any element by its index, location and attributes. However it is impossible to use regular expressions as a part of XPath statements. In most cases this limitation is not critical. XPath itself allows using set of functions covering possible needs for searching an element in an advanced manner.
- XPath is a tool for finding the location of an element based on the Document Object Model (DOM) within a web browser. The DOM representation of a web page differ in some aspects between browsers. In many cases this difference is not critical and may be ignored by use of proper XPath statements.
Xpath Syntax
XPath uses path expressions to select nodes in an XML document. The node is selected by following a path or steps. The most useful path expressions are listed below:
Expression | Description |
nodename | Selects all child nodes of the named node |
/ | Selects from the root node |
// | Selects nodes in the document from the current node that match the selection no matter where they are |
. | Selects the current node |
.. | Selects the parent of the current node |
@ | Selects attributes |
In the table below we have listed some path expressions and the result of the expressions:
Path Expression | Result |
bookstore | Selects all the child nodes of the bookstore element |
/bookstore | Selects the root element bookstore Note: If the path starts with a slash ( / ) it always represents an absolute path to an element! |
bookstore/book | Selects all book elements that are children of bookstore |
//book | Selects all book elements no matter where they are in the document |
bookstore//book | Selects all book elements that are descendant of the bookstore element, no matter where they are under the bookstore element |
//@lang | Selects all attributes that are named lang |
See the cheat sheet for more details.
Browser-specific XPath Implementation
- Internet Explorer does not have a native XPath engine. By default Rapise re-uses the JavaScript based implementation by Cybozu Labs, Inc.
- Firefox has a native XPath implementation
- Chrome has a native XPath implementation
Working with Framesets
Web pages sometimes use HTML frames. The XPath works inside the frame contents. We use following syntax to combine multiple XPath statements into a single line:
//frame[@name='main']@@@//a[3]
The special statement:
@@@
Is used as a separator for XPath statements pointing to constituent frames.
The top-level frame is found by name 'main'
//frame[@name='main']
Then the frame's contents are searched for the third <a> element (i.e. 3rd link inside the frame).
//a[3]
Working with Data Tables
Web pages will often represent the results of searches and queries as formatted tables. As described in the HTML tables guide, you can use XPath to make the verification of such results much easier.
Using the Rapise Web Spy
Each major browser provides a number of standard ways to check the DOM in addition to available plugins and extensions. In addition, since Rapise v3.1, Rapise provides its own powerful WebSpy tool that can inspect any of the web browsers it supports.
To open up the Web Spy, open up Rapise and under the main Spy ribbon icon, select 'Web Spy'. Then click on the Web Spy in the ribbon or on the main recording activity dialog box. This will display the Rapise web spy:
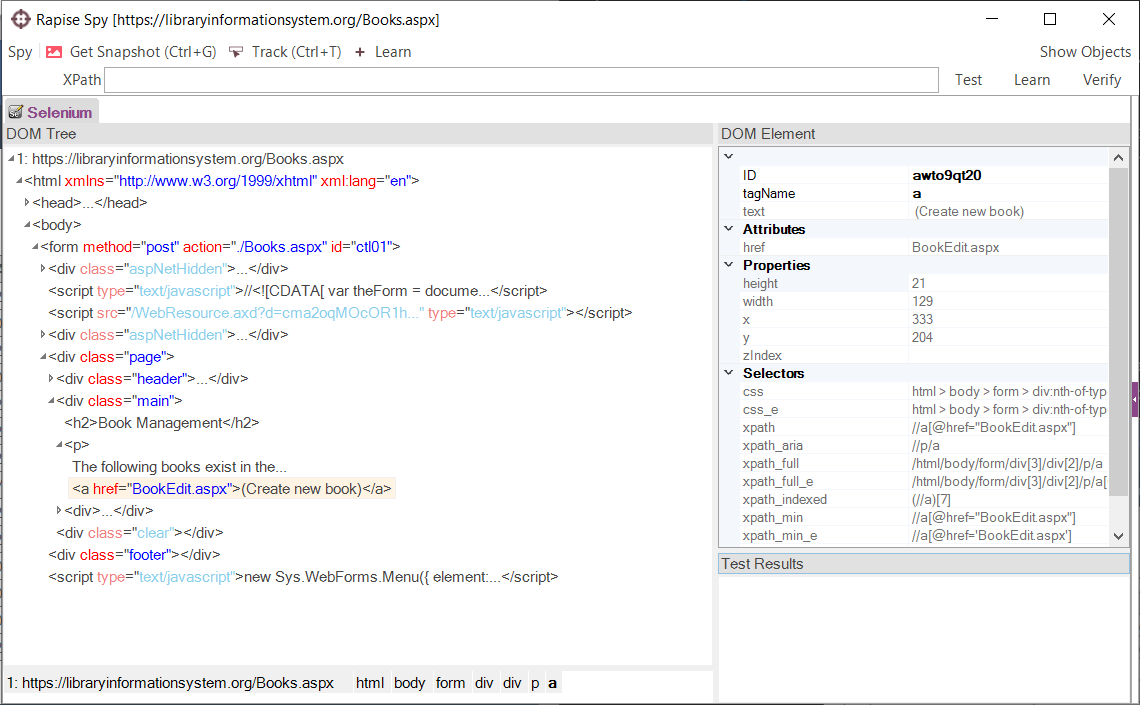
You can learn about using the Rapise Web Spy in this article.
API for DOM Manipulation
Upon learning a web element in Rapise, you get an object of type HTMLObject . Each HTMLObject provides set of functions to facilitate the cross-browser access to web element parents and children.