Consider the following DOM tree from a potential real world application:
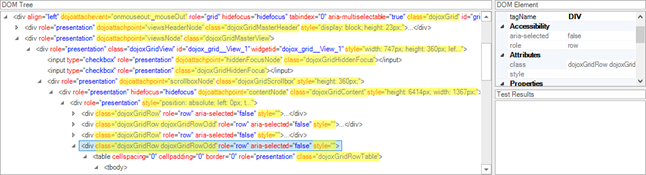
This examples comes from a Dojo-based grid control. We can see that most nodes have redundant attributes, that are used by Dojo internally but should be ignored when building XPath. In this particular case they are:
- “style”. This attribute may change during playback due to its pure visual nature. Also it is likely to be a subject of frequent change by developers because it is sensitive to visual presentation that is influenced by styling, positioning and app face lifting. So it is better to avoid using it in the XPath generation.
- “class”. It is common to use the CSS “class” and change it dynamically to reflect the visual state of the object. For example in this case, class is used to reflect even/odd rows of the grid. It is therefore a common requirement to ignore class in the XPath because it may change dynamically and reflect not only the node but also its current state (bold, selected, focused etc). So class may be used in a manner similar to “style” and thus should be avoided form the XPath generation if possible.
- Some sites use custom attributes. For example, in this case we have “dojoattachevents” and “dojoattachpoint”. We don’t know the real semantic for these attributes, so it is hard to rely on them without additional knowledge of the UI framework. So we want to stick with the standard attributes.
In the image above, we went ahead and marked the ‘bad’ attributes in yellow.
Filtering Attributes
Now we see that it is more convenient to hide some attributes to make the DOM tree simpler and easier to read. We may control which attributes to show (include) OR display all attributes except some that should be excluded. In this case the tree will look much cleaner.
The user has control on how the attributes are displayed through the WebSpy options dialog:
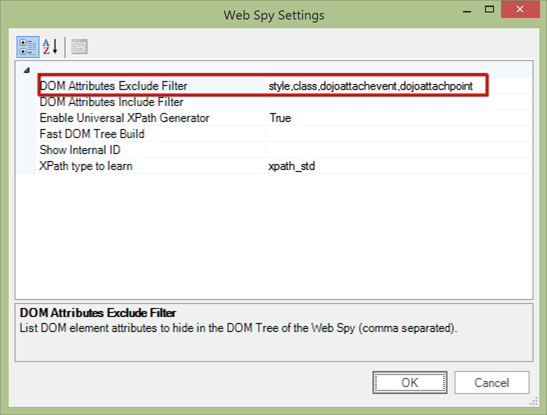
In this example, we defined the “DOM Attributes Exclude Filter” as “style, class, dojoattachevent, dojoattachpoint”. So once we re-load the DOM tree (Ctrl+G) we see the tree much in a much cleaner way:
