For illustration we'll use the following page opened in Firefox:
https://www.w3schools.com/bootstrap4/tryit.asp?filename=trybs_toast&stacked=h
It contains a button that triggers a toast message. The message is displayed for 1 second.

Here is the page source:
<div class="container">
<h3>Toast Example</h3>
<p>A toast is like an alert box that is only shown for a couple of seconds when something happens (i.e. when a user clicks on a button, submits a form, etc.).</p>
<p>In this example, we use a button to show the toast message.</p>
<button type="button" class="btn btn-primary" id="myBtn">Show Toast</button>
<div class="toast">
<div class="toast-header">
Toast Header
</div>
<div class="toast-body">
Some text inside the toast body
</div>
</div>
</div>
We'll need the source because it is very hard to learn or record elements that appear for 1 second.
Step 1: Record actions that lead to a toast message
Record click on Show Toast button.

Step 2: Build XPath of the toast message
XPath recorded for Show Toast is
//iframe[@name='iframeResult' and @id='iframeResult']@@@//button[@id='myBtn']
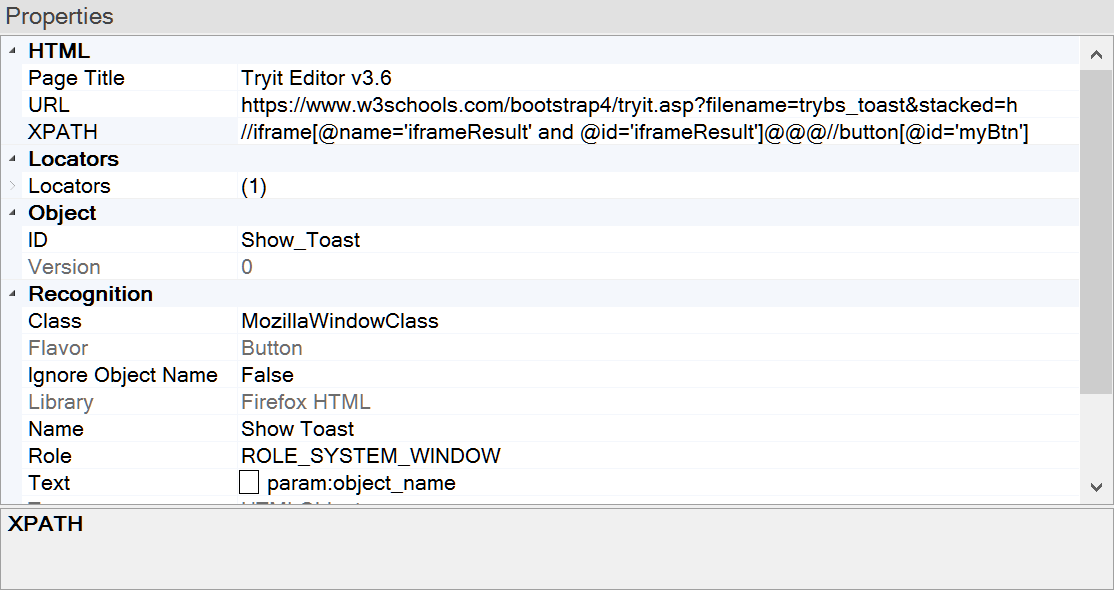
We see that the button and the toast are inside a frame. Based on this knowledge and class of the toast message (toast-body) that we determine from the source we can now write an XPath for the toast body:
//iframe[@id='iframeResult']@@@//div[@class='toast-body']
Step 3: Check for the toast message
Now we can use Navigator.Find to search for the toast message.
https://rapisedoc.inflectra.com/Libraries/Navigator/#Find
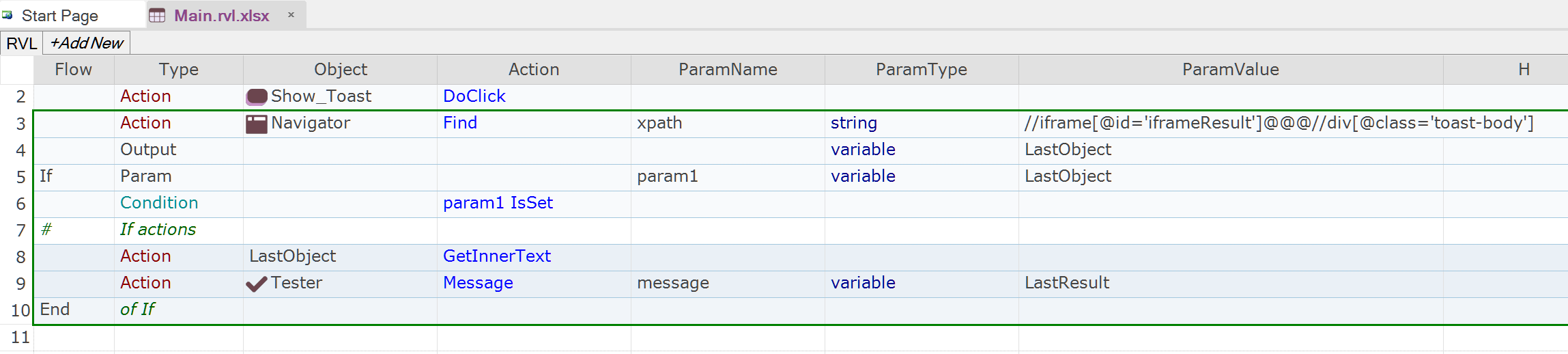
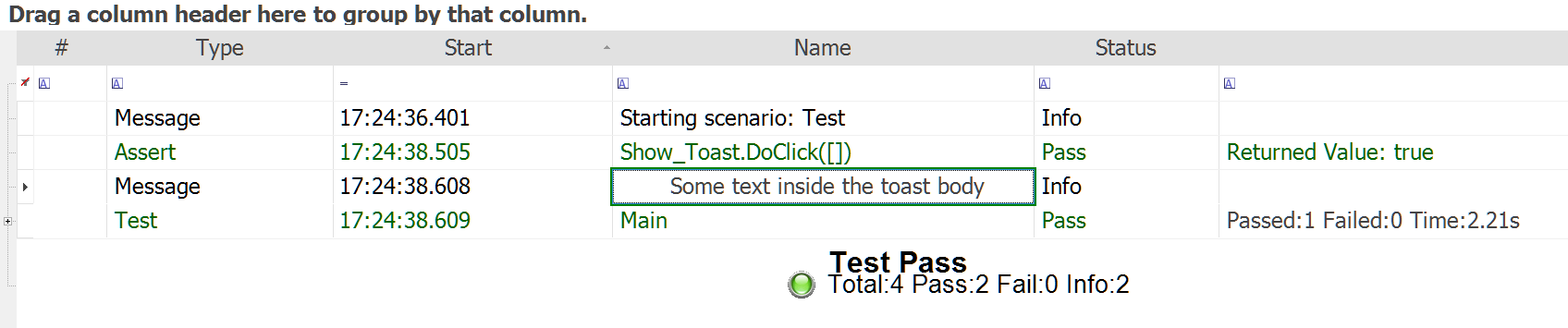
On the line 4 we store result of the Navigator.Find into predefined variable LastObject. Then we check for the message. If the toast message is found - print it's content to the report. On the line 8 we read inner text of the message element. On the line 9 we use the result of GetInnerText stored into predefined variable LastResult.
https://rapisedoc.inflectra.com/Libraries/HTMLObject/#InnerText
In JavaScript the code checking for the toast message looks this way:
SeS('Show_Toast').DoClick();
var obj = Navigator.Find("//iframe[@id='iframeResult']@@@//div[@class='toast-body']");
if(obj)
{
var text = obj.GetInnerText();
Tester.Message(text);
}