Adding the PDF Public Module
The first thing you need to do is import the special PDF Public Module into your Rapise test framework:
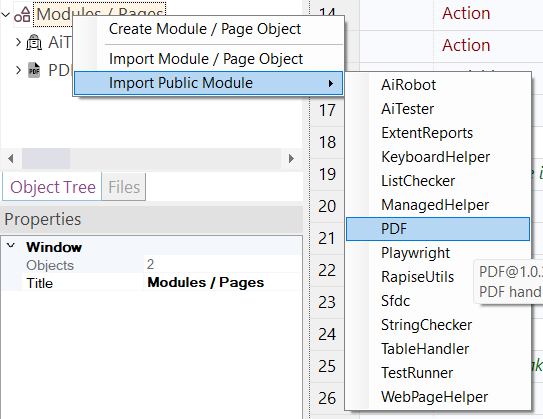
Once that has been added, it will be visible in your test framework:

Using the PDF Public Module
Once that is done, you can now use the PDF module in RVL to easily check that the attached PDF file contains specific text using the AssertContains method:

where the parameters are as follows:
- pdfPath path to the PDF file
- textOrRegexp substring to locate either as text or a regular expression
- assertionMessage - optional assertion message to include into the report.
The equivalent JavaScript expression would be:
PDF.AssertContains("Does not contain the word Invoice!", "C:\\Users\\xxxxxxx\\Documents\\My Rapise Tests\\PDF Testing\\TestCases\\InflectraInvoice_162733.pdf", "Invoice");
when you want to check for the absence of a piece of text, you will need to use the more general Assert method and add an explicit Assert statement:

where the parameters are as follows:
- pdfPath path to the PDF file
- textOrRegexp substring to locate either as text or a regular expression
The equivalent JavaScript expression would be:
Tester.Assert("Does contain the word Refund incorrectly!", PDF.Contains("C:\\Users\\xxx\\Documents\\My Rapise Tests\\PDF Testing\\TestCases\\InflectraInvoice_162733.pdf", "Refund")==false );
Finally, in some situations you need to extract all of the text of the PDF file, in which case, you can use the GetFullText method:

where the parameters are as follows:
- pdfPath path to the PDF file
The equivalent JavaScript expression would be:
PDF.GetFullText("C:\\Users\\xxx\\Documents\\My Rapise Tests\\PDF Testing\\TestCases\\NOAQDWI.pdf");
CleanPDFText(LastResult);
var FullText = LastResult;
Tester.Message(FullText);
In this example, we're using a custom function to do some cleaning on the PDF text (e.g. removing all whitespace) to make it easier to parse:
//Removes any extra spaces that can sometimes be included in PDFs when we extract the text
function CleanPDFText(text)
{
return text.replaceAll(/\s/g, '');
}